Building a Networking Layer with Operations
Sometimes the tools that make our lives easier also make our architecture worse. When something is hard to do, we build structure around it, and that structure often leads us to make smarter decisions and be more thoughtful with what does what. When a new tool removes that difficulty, we remove the structure with it - and in doing so, lose the benefits we never even realised the structure gave us.
When NSURLConnection was the only networking option on iOS, its delegate-based approach required so much boilerplate that developers naturally pushed networking code out of their view controllers and into dedicated classes. The boilerplate was tedious, but it had an architectural side effect worth preserving - a distinct networking layer with clear responsibilities. When URLSession was released with its far more developer-friendly, closure-based interface, we jumped at the chance to remove all that boilerplate. But the ease of making network calls meant that we no longer had to keep networking at arm's length. Network requests, JSON parsing, and response handling started appearing directly in view controllers alongside their existing responsibilities 💥 - a quiet erosion of the single responsibility principle that made our codebases harder to understand and more brittle to change.
This post will explore how we can use Operation and OperationQueue to get back to an isolated networking layer.
Looking at What We Need to Build
Whenever I think of layers in software engineering, I always picture that great engineering marvel: the Hoover Dam.

A very visible, physical divider between two different domains - the reservoir before and the river after. For the water to continue to flow through the canyons, it must pass through the dam in a manner dictated by the dam itself - just like how data flows around a system based on an agreed contract.
Our networking layer will have three main responsibilities:
- Scheduling network requests
- Performing networking requests
- Parsing the response from network requests
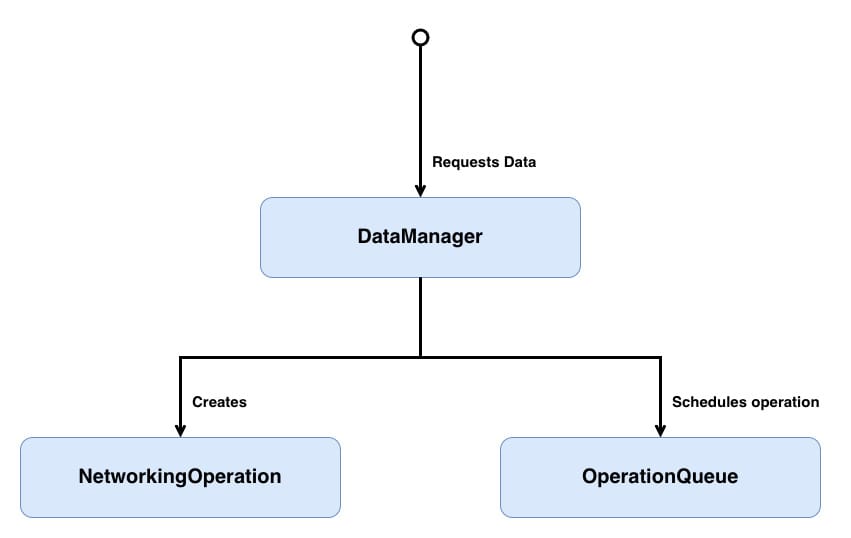
DataManager- responsible for abstracting away the operation creation and passing that operation to theOperationQueue.NetworkingOperation- a concurrent operation that will configure and then make a network request for a particular endpoint. It will then process the response from that network request.OperationQueue- the standard iOS operation queue that manages the scheduling and execution of operations.
I've used generic naming in the class diagram, but in the example, we will be working in concrete types, so
DataManagerwill becomeQuestionsDataManager, andNetworkingOperationwill become a combination ofConcurrentOperationandQuestionsFetchOperation.
Don't worry if that doesn't all make sense yet; we will look into each component in greater depth below.
Just like with the Hoover Dam, our networking layer will have a well-encapsulated outer edge that will transform data requests into distinct tasks, which will then be scheduled for execution. Each task will consist of the actual network request and its response parsing 🌹.
Before jumping into building each component, let's take a small recap of what OperationQueue and Operation are.
OperationQueue is responsible for coordinating the execution of operations. Rather than executing work immediately, it schedules operations based on each operation's readiness, priority, dependencies, and available system resources.
Because OperationQueue maintains visibility over its operations, we can inspect, pause, or cancel them - for example, cancelling in-flight requests when a user logs out.
Under the hood, OperationQueue leverages GCD, allowing it to take advantage of multiple cores without the developer needing to manage threads directly. By default, it will execute as many operations in parallel as the device can reasonably support.
Operation is an abstract class which needs to be subclassed to undertake a specific task. An Operation typically runs on a separate thread from the one that created it. Each operation is controlled via an internal state machine; the possible states are:
Pendingindicates that the operation has been added to the queue.Readyindicates that the operation is good to go, and if there is space on the queue, this operation's task can be started.Executingindicates that the operation is actually doing work at the moment.Finishedindicates that the operation has completed its task and should be removed from the queue.Cancelledindicates that the operation has been cancelled and should stop its execution.
A typical operation's lifecycle will move through the following states:
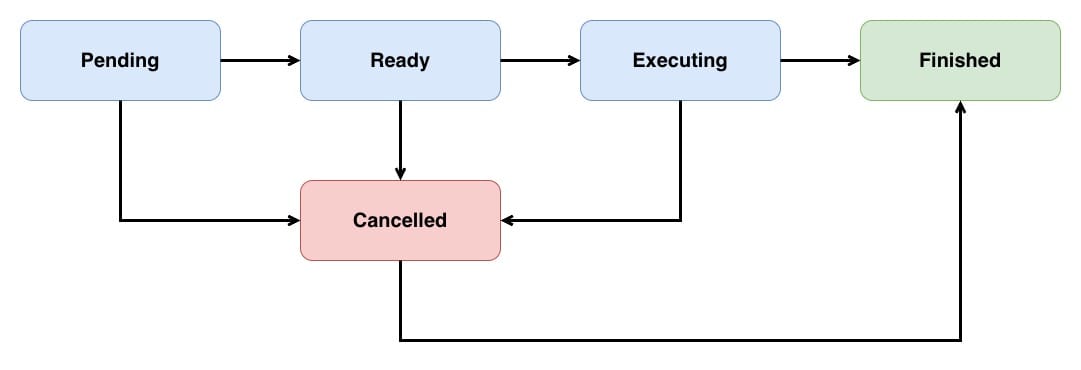
It's important to note that cancelling an executing operation will not automatically stop that operation; instead, it is up to the individual operation to clean up after itself and transition into the Finished state.
Operations come in two flavours:
- Non-Concurrent
- Concurrent
Non-Concurrent operations perform all their work on the same thread, so that when the main method returns, the operation is moved into the Finished state. The queue is then notified of this and removes the operation from its active operation pool, freeing resources for the next operation.
Concurrent operations can perform some of their work on a different thread, so returning from the main method can no longer be used to move the operation into a Finished state. Instead, when we create a concurrent operation, we assume the responsibility for moving the operation between the Ready, Executing, and Finished states.
Unsurprisingly, given its name, our ConcurrentOperation will be a concurrent operation.
This post will gradually build up to a working example. But if you can't wait, then head on over to the completed example to see how things end up.
Building Our Concurrent Operation 🏗️
A networking operation is a specialised concurrent operation because when an URLSession makes a network request, it does so on a different thread from the thread that resumed that task. While each endpoint is unique, we can share some functionality between these different endpoints by writing a parent operation that all the endpoint-specific operations can inherit from:
// 1
class ConcurrentOperation<Value>: Operation {
// 2
private(set) var completionHandler: ((_ result: Result<Value, Error>) -> Void)?
init(completionHandler: ((_ result: Result<Value, Error>) -> Void)?) {
self.completionHandler = completionHandler
super.init()
}
}Here's what we did above:
ConcurrentOperationis a generic subclass ofOperation- theValuetype parameter lets each operation define what type of data it produces on completion.- The
completionHandlerclosure usesResult<Value, Error>to deliver either the operation's value or an error back to the caller. TheValuesuccess type is tied to the operation's generic parameter, so aConcurrentOperation<Data>will produce aResult<Data, Error>, keeping things type-safe from creation through to completion. The handler isprivate(set)so that callers can read but not replace it after initialisation.
As mentioned, a concurrent operation takes responsibility for ensuring that its internal state is correct. This state is controlled by manipulating the isReady, isExecuting and isFinished properties. However, these are read-only, so these properties will need to be overridden so that we can set them. When mapping state, enums work best:
class ConcurrentOperation<Value>: Operation {
// 1
private enum State {
case ready
case executing
case finished
}
// 2
private var state = State.ready
// 3
override var isReady: Bool {
return super.isReady && state == .ready
}
// 4
override var isExecuting: Bool {
return state == .executing
}
// 5
override var isFinished: Bool {
return state == .finished
}
}- A private enum representing the three operation states that we will control to make
ConcurrentOperationinto a concurrent operation. - The operation starts in the
readystate. - Maps
isReadyto use both ourstatevalue and the superclassisReadyvalue -super.isReadyis managed internally byOperationand tracks things like whether dependencies have finished. By combining them, the operation is only considered ready when bothisReadyvalues aretrue. By caring aboutsuper.isReady, we continue to allow for dependency management to work with our concurrent operations as it does for non-concurrent operations. - Maps
isExecutingto our internal state. - Maps
isFinishedto our internal state. When this returnstrue, theOperationQueueknows to remove the operation from the queue.
OperationQueue uses KVO to know when its operations change state so that it can control the flow of operations. Let's add in KVO support:
class ConcurrentOperation<Value>: Operation {
// Omitted other functionality
// 1
enum State: String {
case ready = "isReady"
case executing = "isExecuting"
case finished = "isFinished"
}
var state = State.ready {
// 2
willSet {
willChangeValue(forKey: state.rawValue)
willChangeValue(forKey: newValue.rawValue)
}
// 3
didSet {
didChangeValue(forKey: oldValue.rawValue)
didChangeValue(forKey: state.rawValue)
}
}
}- Each enum case's raw value matches the corresponding
Operationproperty name. This lets us use the raw value directly as theKVOkey when notifying observers of state changes. - Before the state changes, we notify
KVOobservers that both the new state's property and the current state's property are about to change. For example, transitioning fromreadytoexecutingtells observers that bothisExecutingandisReadyare about to change. - After the state changes, we notify
KVOobservers that the transition is complete.OperationQueuerelies on these KVO notifications to know when an operation has started, finished, or is ready to execute - without them, the queue won't respond to state changes.
With KVO support implemented, let's add in the lifecycle methods to move through the various states:
// 1
enum ConcurrentOperationError: Error, Equatable {
case cancelled
}
class ConcurrentOperation<Value>: Operation {
// Omitted other functionality
// 2
override func start() {
// 3
guard !isCancelled else {
finish(result: .failure(ConcurrentOperationError.cancelled))
return
}
// 4
state = .executing
// 5
main()
}
// 6
func finish(result: Result<Value, Error>) {
guard !isFinished else {
return
}
state = .finished
// 7
completionHandler?(result)
}
// 8
override func cancel() {
super.cancel()
finish(result: .failure(ConcurrentOperationError.cancelled))
}
}- A custom error type for cancellation.
- We override
startrather thanmainbecause this is a concurrent operation - we're taking responsibility for managing state transitions ourselves. It's important to note thatsuper.start()isn't being called intentionally, as by overridingstart, this operation assumes full control of maintaining its state. - If the operation was cancelled before it started, we deliver a cancellation error to
completionHandlerand transition tofinished. - Transitions the operation into the
executingstate, triggering KVO notifications that tell the queue the operation is now active. - Calls
mainwhere subclasses perform their actual work. Subclasses callfinish(result:)when their work is done.mainis the entry point for non-concurrent operations. By choosingmainto be the entry point for our concurrent operation, the cognitive load on any future developer is reduced, as it allows them to transfer the expectation of how non-concurrent operations work to our concurrent operation implementation. finish(result:)is the single exit point for delivering a result. Theguard !isFinishedprevents double-finishing, which could happen ifcanceland the operation's work complete at roughly the same time. It's essential that all operations eventually call this method. If you are experiencing odd behaviour where your queue seems to have jammed, and no operations are being processed, one of your operations is probably missing a finish call somewhere.- The completion handler is called with the result.
cancelcallssuper.cancel()to set theisCancelledflag, then immediately delivers a cancellation error viafinish(result:). This ensures the operation always reaches thefinishedstate as Apple's documentation requires -cancelledalone is not a valid end state.
In
finish(result:),completionHandleris called on whatever thread theURLSessionDataTaskcompletion closure runs on - most likely a background thread. We could pass in a callback queue thatcompletionHandlerwill be dispatched onto to better control this behaviour. I haven't done so here to keep this example as simple as possible, but if you want that functionality, readAvoid Queue-Jumpingfor details on how to define the callback queue.
All that's left to do state-wise is to indicate that this is an asynchronous operation by overriding isAsynchronous:
class ConcurrentOperation<Value>: Operation {
// Omitted other functionality
override var isAsynchronous: Bool {
return true
}
}As ConcurrentOperation subclasses are always expected to be executed via an OperationQueue, overriding isAsynchronous is strictly not needed, but we override it here to express intent clearly. isAsynchronous only matters if we call start directly on the operation without a queue. In that case, the caller is supposed to check isAsynchronous to decide whether to spin up a separate thread.
We've taken over the state management for ConcurrentOperation, but as it stands ConcurrentOperation has multiple race conditions that could cause crashes or undefined behaviour if the mutable state is updated from different threads. Let's protect against that by using a NSRecursiveLock to ensure only one thread can mutate state at any given moment:
class ConcurrentOperation<Value>: Operation {
// Omitted unchanged functionality
// 1
private let lock = NSRecursiveLock()
// 2
private var _state = State.ready {
willSet {
willChangeValue(forKey: _state.rawValue)
willChangeValue(forKey: newValue.rawValue)
}
didSet {
didChangeValue(forKey: oldValue.rawValue)
didChangeValue(forKey: _state.rawValue)
}
}
// 3
private var state: State {
get {
lock.lock()
defer { lock.unlock() }
return _state
}
set {
lock.lock()
defer { lock.unlock() }
_state = newValue
}
}
// Omitted unchanged functionality
// 4
func finish(result: Result<Value, Error>) {
lock.lock()
defer { lock.unlock() }
// Omitted unchanged functionality
}
}- The recursive lock that will be used to synchronise access to shared mutable state -
stateandcompletionHandler. It's recursive becauseKVOcreates re-entrant calls: when the setter updates_state,KVOnotifications fire synchronously, which causesOperationQueueto readisFinished/isExecuting/isReady, which calls the getter, which needs to acquire the same lock on the same thread. A non-recursive lock, or dispatch queue, would deadlock here. - The backing storage
_stateseparates the raw value from the thread-safe accessor. TheKVOnotifications inwillSetanddidSetremain on the backing property so they fire within the lock - ensuring observers always see a consistent state. - The thread-safe accessor for state. Both the getter and setter acquire the lock before accessing
_state. Thedeferensures the lock is always released. finish(result:)acquires the lock to ensure that readingisFinishedand updatingstateandcompletionHandlerhappens atomically.
See
Threading Programming Guidefor more details on thread safety.
Technically, using a lock will block the calling thread, which could be themainthread. I could have exposed this blocking, but I've decided thatConcurrentOperationshould silently absorb that blocking behaviour, to keep its API simple. Due to this silent blocking, undertaking any significant work insidecompletionHandlershould be avoided or moved onto a different thread.
With ConcurrentOperation now thread-safe, it's time to write some networking code.
Making a Network Request
StackOverflow has an excellent, open API that will be used below to build a networking operation. The networking operation will retrieve and parse the latest questions via the questions endpoint.
// 1
enum NetworkingError: Error, Equatable {
case missingData
case serialization
case invalidStatusCode(Int)
}
// 2
class QuestionsFetchOperation: ConcurrentOperation<[Question]> {
// 3
private var task: URLSessionDataTask?
// 4
override func main() {
// 5
let url = URL(string: "https://api.stackexchange.com/2.3/questions?site=stackoverflow")!
var urlRequest = URLRequest(url: url)
urlRequest.httpMethod = "GET"
// 6
task = URLSession.shared.dataTask(with: urlRequest) { (data, response, error) in
// 7
if let error = error {
self.finish(result: .failure(error))
return
}
guard let httpResponse = response as? HTTPURLResponse else {
self.finish(result: .failure(NetworkingError.missingData))
return
}
guard (200...299).contains(httpResponse.statusCode) else {
self.finish(result: .failure(NetworkingError.invalidStatusCode(httpResponse.statusCode)))
return
}
guard let data = data, !data.isEmpty else {
self.finish(result: .failure(NetworkingError.missingData))
return
}
do {
// 8
let questionPage = try JSONDecoder().decode(QuestionPage.self,
from: data)
self.finish(result: .success(questionPage.items))
} catch {
// 9
self.finish(result: .failure(NetworkingError.serialization))
}
}
task?.resume()
}
// 10
override func cancel() {
task?.cancel()
super.cancel()
}
}NetworkingErrordefines the error cases specific to our networking layer - missing data, serialisation failures, and invalid HTTP status codes.QuestionsFetchOperationsubclassesConcurrentOperationwith aValueof[Question], meaning its completion handler will deliver aResult<[Question], Error>.- The
taskproperty holds a reference to the in-flight URL session data task so that it can be cancelled later if needed. main()is the entry point thatConcurrentOperationcalls once the operation begins executing. Note that we don't override thestart()method that we created inConcurrentOperation.- We build the URL request targeting the Stack Exchange API's
questionsendpoint. - A data task is created and kicked off with
resume(). The completion closure capturesselfto callfinish(result:)once the network call returns. The closure captures self strongly - this is safe because URLSessionDataTask releases its completion closure after execution, breaking the retain cycle. - Before we attempt to decode, we walk through a series of guard checks - verifying there's no transport error, that we received an HTTP response, that the status code falls within the 2xx range, and that the response body isn't empty. Each failing guard finishes the operation with the appropriate error.
- On the happy path, we decode the response into a
QuestionPageand finish with.success, passing along the array ofQuestionitems. - If decoding fails, we finish with a
.failurewrapping a serialisation error. cancel()cancels the in-flight data task before callingsuper.cancel(), which triggersConcurrentOperation's own cancellation logic - finishing the operation with a.cancellederror.
QuestionPageis a model struct that will be populated with the questions endpoint JSON response. I won't show in this post, but if you are interested, then head on over to the completed example.
And that's essentially what a networking operation looks like. Of course, each different network operation will be unique, but the general structure will be similar to QuestionsFetchOperation.
You might be thinking: "Why can't the network request be sync, we are already in a concurrent context?"
The key thing is that
OperationQueuehas a finite number of threads it can use. It draws from the thread pool ofGCD, and that pool has a practical ceiling - around 64 threads, though it varies. Each operation that's executing claims one of those threads.With an async call, the timeline looks something like: the operation starts on a thread, kicks off the request, and the thread is returned to the pool while the networking subsystem handles the waiting. When the response arrives, a thread is picked up again to process it. The operation is "executing" the whole time, but it's only occupying a thread for the brief moments where it's actually doing CPU work.
With a sync call, the operation starts on a thread, and that thread just sits there, blocked, until the response comes back. If the server is slow or the connection is poor, that could be seconds. Multiply that across several operations running in parallel, and you're burning through the thread pool on operations that aren't actually doing anything. In the worst case, you could saturate the pool, and other work - not just your network requests, but anything else using
GCD- starts queuing up waiting for a thread to free up.So the async approach isn't just about being polite to the system. It's about not turning our operation queue into a thread-hoarding bottleneck when the network gets slow.
Scheduling Network Requests
So far, 2 of the 3 responsibilities of the networking layer shown above have been built:
Performing networking requestsParsing the response from network requests
Time to look at the final responsibility:
Scheduling network requests.
If we refer back to the class structure above, this responsibility is handled by the DataManager:
// 1
class QuestionsDataManager {
// 2
private let queue: OperationQueue
init(queue: OperationQueue) {
self.queue = queue
}
// 3
func fetchQuestions(completionHandler: @escaping (_ result: Result<[Question], Error>) -> Void) {
let operation = QuestionsFetchOperation(completionHandler: completionHandler)
queue.addOperation(operation)
}
}QuestionsDataManageracts as the entry point for the rest of the app to request data - it hides the fact that operations are being used under the hood.- The
OperationQueueis injected through the initialiser rather than created internally, giving the caller control over concurrency limits and making the class easier to test. fetchQuestionswraps the creation and scheduling of aQuestionsFetchOperationinto a single method call. The caller just provides a completion handler, and the manager takes care of building the operation, passing that handler through, and adding it to the queue.
QuestionsDataManager is our dam. It's the boundary that the rest of the app interacts with - callers ask for questions and receive a result, with no awareness that operations, queues, or state machines exist behind it. That separation allows the networking layer to be configured however we choose without those implementation details leaking out. If we later decide to swap operations for a GCD solution, or add caching, or switch to a different API client, nothing outside the data manager needs to change.
And with that, all three responsibilities are now in place! 🪇
Looking at What We Have
In some ways, we got lucky that NSURLConnection was hard to use. That difficulty forced us to build structure around our networking code, and that structure led us to make smarter decisions about where functionality lived.
When URLSession removed the difficulty, the structure went with it.
Building a networking layer around Operation isn't about making things harder again. It's about restoring the boundaries that keep responsibilities clear.
To see the complete working example, visit the repository and clone the project.
Note that the code in the repository is unit tested, so it isn't 100% the same as the code snippets shown in this post. The changes mainly involve a greater use of protocols to allow for test-doubles to be injected into the various types. While not hugely different, I didn't want to present the increased complexity necessary for unit testing to get in the way of the core message in this post.